
Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Each successive model offers increasingly powerful performance, allowing users to select the optimal balance of intelligence, speed, and for their specific application.
Opus and Sonnet are now available to use in claude.ai and the Claude API which is now generally available in 159 countries. Haiku will be available soon.
Claude 3 model family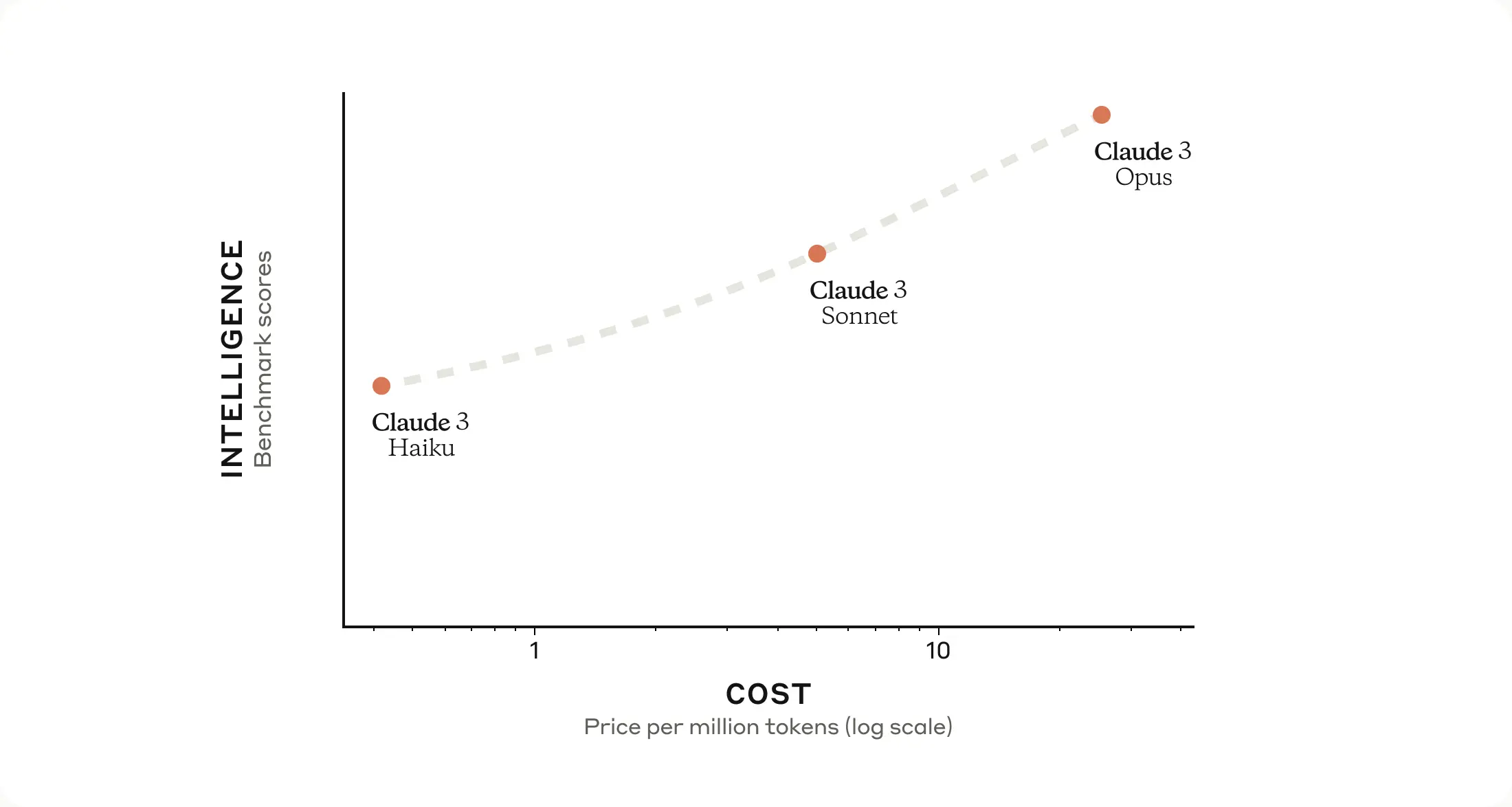
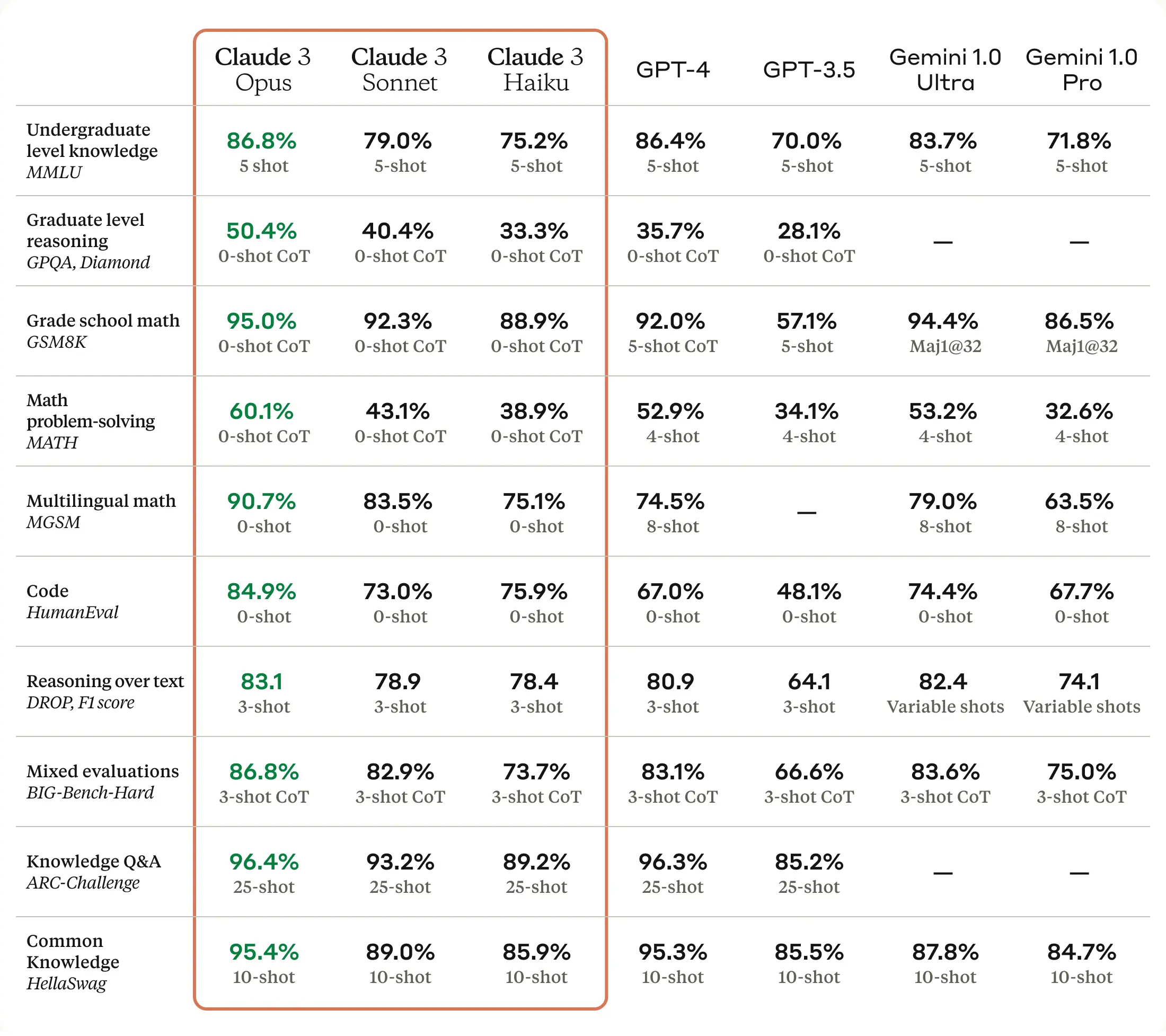
Opus, our most intelligent model, outperforms its peers on most of the common evaluation benchmarks for AI systems, including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), basic mathematics (GSM8K), and more. It exhibits near-human levels of comprehension and fluency on complex tasks, leading the frontier of general intelligence.
All Claude 3 models show increased capabilities in analysis and forecasting, nuanced content creation, code generation, and conversing in non-English languages like Spanish, Japanese, and French.
Below is a comparison of the Claude 3 models to those of our peers on multiple benchmarks [1] of capability:
The Claude 3 models can power live customer chats, auto-completions, and data extraction tasks where responses must be immediate and in real-time.
Haiku is the fastest and most cost-effective model on the market for its intelligence category. It can read an information and data dense research paper on arXiv (~10k tokens) with charts and graphs in less than three seconds. Following launch, we expect to improve performance even further.
For the vast majority of workloads, Sonnet is 2x faster than Claude 2 and Claude 2.1 with higher levels of intelligence. It excels at tasks demanding rapid responses, like knowledge retrieval or sales automation. Opus delivers similar speeds to Claude 2 and 2.1, but with much higher levels of intelligence.
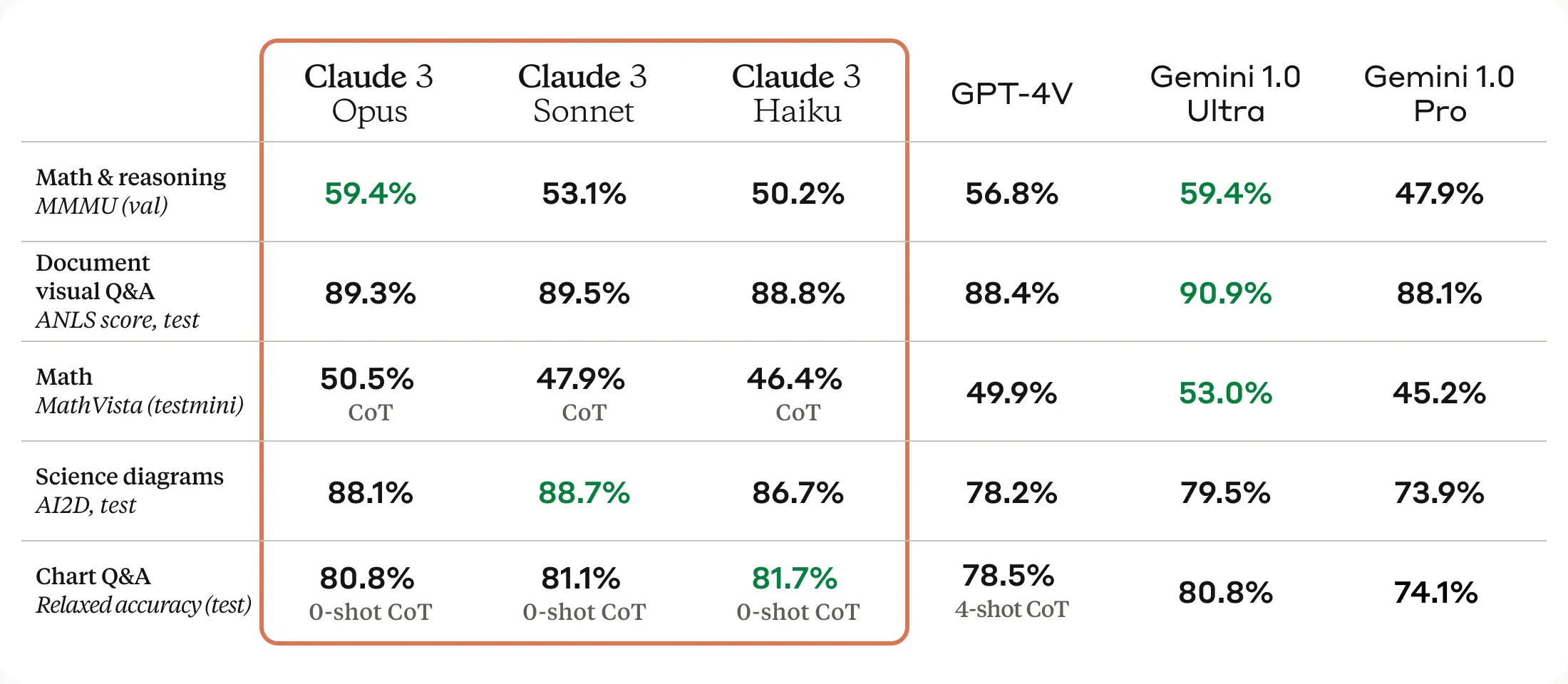
Strong vision capabilitiesThe Claude 3 models have sophisticated vision capabilities on par with other leading models. They can process a wide range of visual formats, including photos, charts, graphs and technical diagrams. We’re particularly excited to provide this new modality to our enterprise customers, some of whom have up to 50% of their knowledge bases encoded in various formats such as PDFs, flowcharts, or presentation slides.
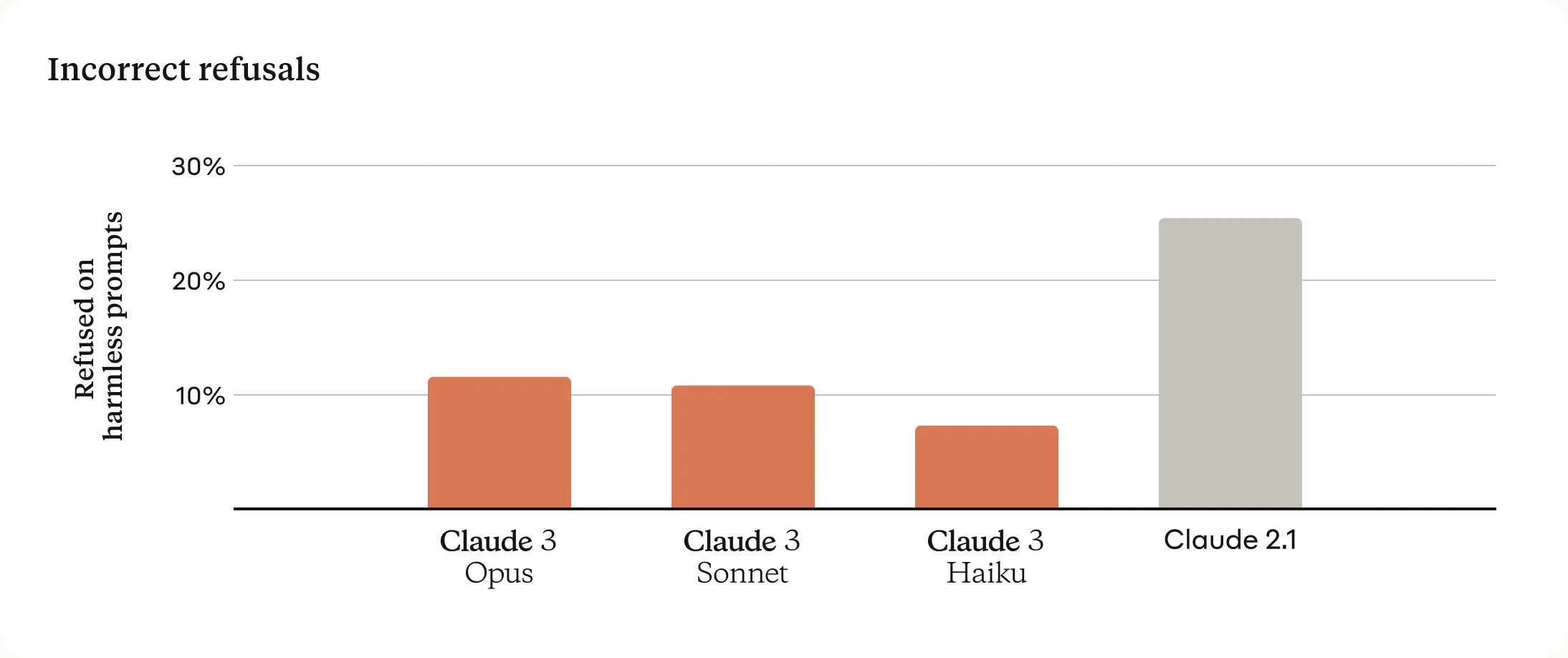
Previous Claude models often made unnecessary refusals that suggested a lack of contextual understanding. We’ve made meaningful progress in this area: Opus, Sonnet, and Haiku are significantly less likely to refuse to answer prompts that border on the system’s guardrails than previous generations of models. As shown below, the Claude 3 models show a more nuanced understanding of requests, recognize real harm, and refuse to answer harmless prompts much less often.
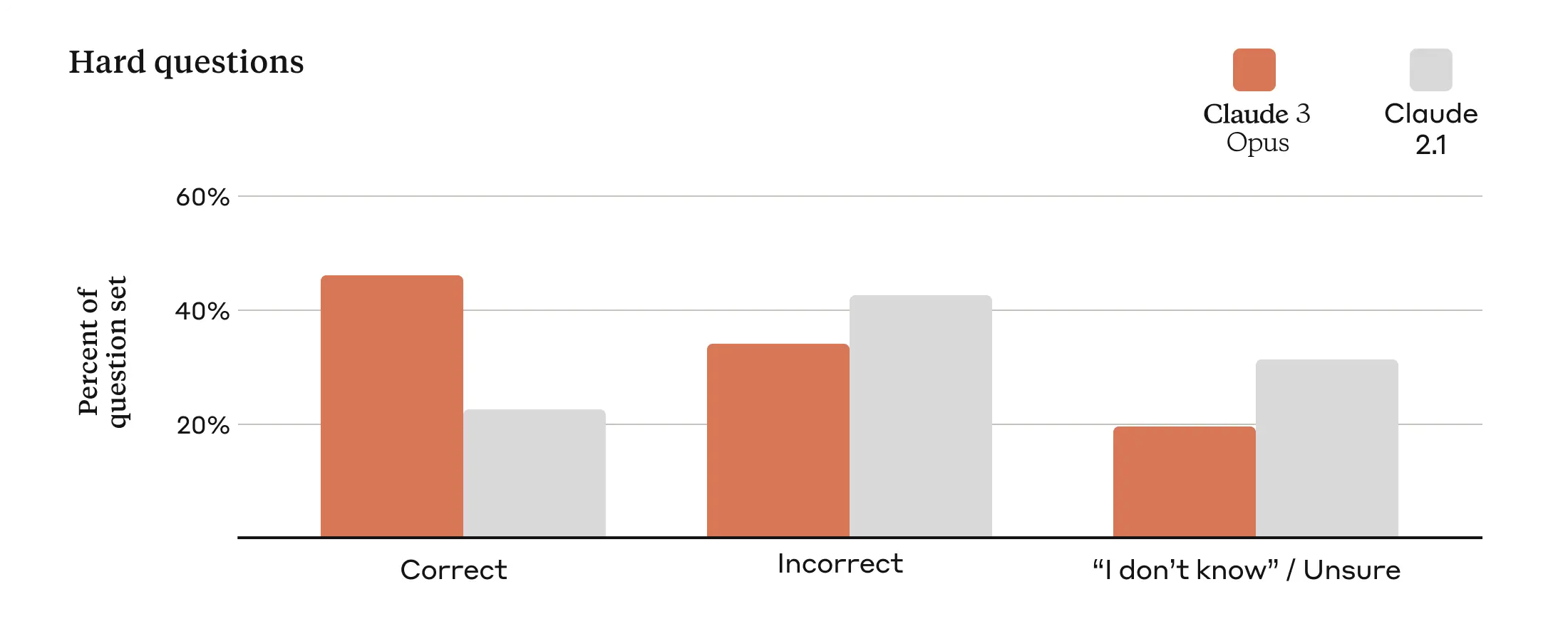
Businesses of all sizes rely on our models to serve their customers, making it imperative for our model outputs to maintain high accuracy at scale. To assess this, we use a large set of complex, factual questions that target known weaknesses in current models. We categorize the responses into correct answers, incorrect answers (or hallucinations), and admissions of uncertainty, where the model says it doesn’t know the answer instead of providing incorrect information. Compared to Claude 2.1, Opus demonstrates a twofold improvement in accuracy (or correct answers) on these challenging open-ended questions while also exhibiting reduced levels of incorrect answers.
In addition to producing more trustworthy responses, we will soon enable citations in our Claude 3 models so they can point to precise sentences in reference material to verify their answers.
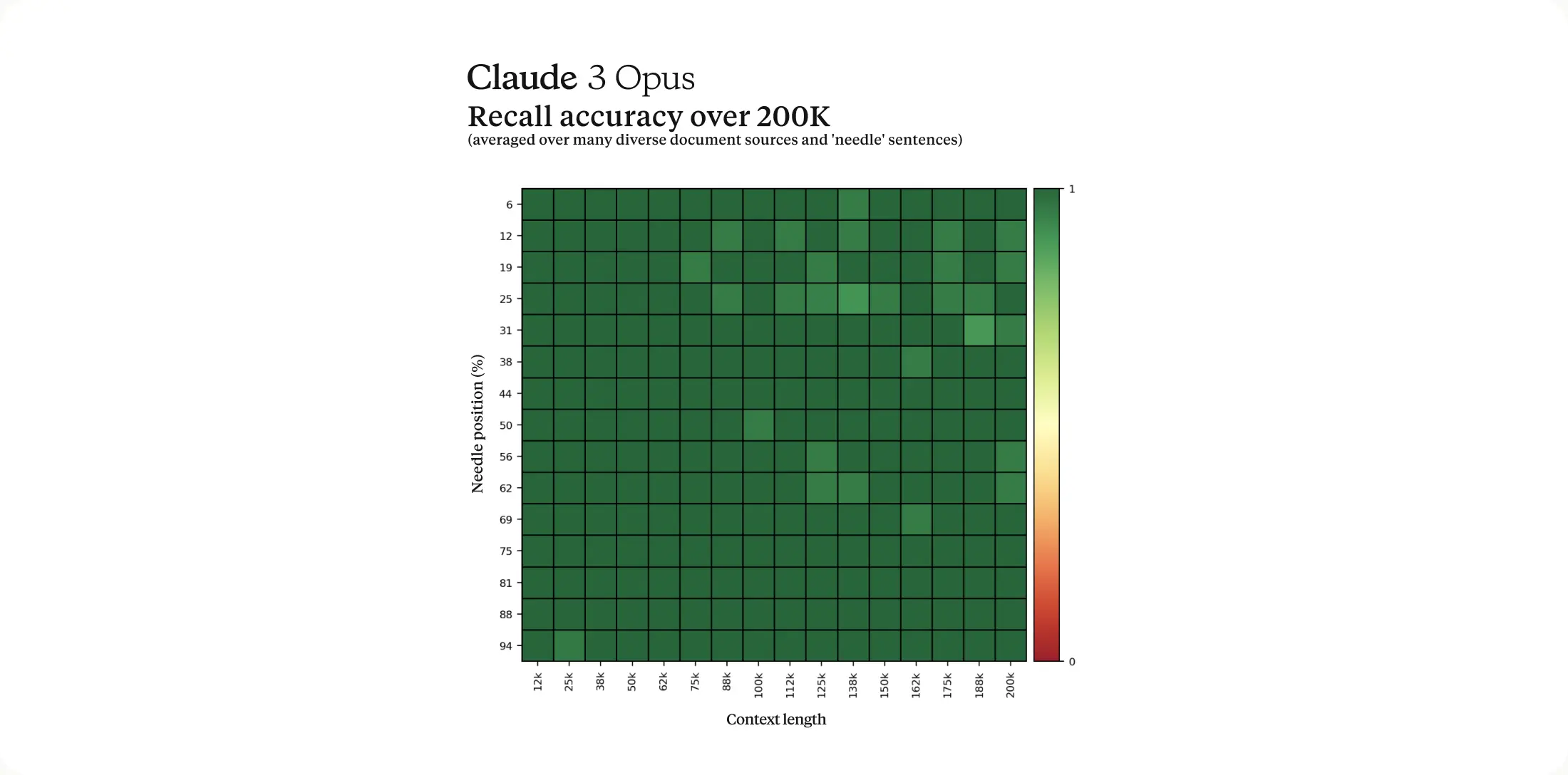
The Claude 3 family of models will initially offer a 200K context window upon launch. However, all three models are capable of accepting inputs exceeding 1 million tokens and we may make this available to select customers who need enhanced processing power.
To process long context prompts effectively, models require robust recall capabilities. The 'Needle In A Haystack' (NIAH) evaluation measures a model's ability to accurately recall information from a vast corpus of data. We enhanced the robustness of this benchmark by using one of 30 random needle/question pairs per prompt and testing on a diverse crowdsourced corpus of documents. Claude 3 Opus not only achieved near-perfect recall, surpassing 99% accuracy, but in some cases, it even identified the limitations of the evaluation itself by recognizing that the "needle" sentence appeared to be artificially inserted into the original text by a human.
We’ve developed the Claude 3 family of models to be as trustworthy as they are capable. We have several dedicated teams that track and mitigate a broad spectrum of risks, ranging from misinformation and CSAM to biological misuse, election interference, and autonomous replication skills. We continue to develop methods such as Constitutional AI that improve the safety and transparency of our models, and have tuned our models to mitigate against privacy issues that could be raised by new modalities.
Addressing biases in increasingly sophisticated models is an ongoing effort and we’ve made strides with this new release. As shown in the model card, Claude 3 shows less biases than our previous models according to the Bias Benchmark for Question Answering (BBQ). We remain committed to advancing techniques that reduce biases and promote greater neutrality in our models, ensuring they are not skewed towards any particular partisan stance.
While the Claude 3 model family has advanced on key measures of biological knowledge, cyber-related knowledge, and autonomy compared to previous models, it remains at AI Safety Level 2 (ASL-2) per our Responsible Scaling Policy. Our red teaming evaluations (performed in line with our White House commitments and the 2023 US Executive Order) have concluded that the models present negligible potential for catastrophic risk at this time. We will continue to carefully monitor future models to assess their proximity to the ASL-3 threshold. Further safety details are available in the Claude 3 model card.
The Claude 3 models are better at following complex, multi-step instructions. They are particularly adept at adhering to brand voice and response guidelines, and developing customer-facing experiences our users can trust. In addition, the Claude 3 models are better at producing popular structured output in formats like JSON—making it simpler to instruct Claude for use cases like natural language classification and sentiment analysis.
Claude 3 Opus is our most intelligent model, with best-in-market performance on highly complex tasks. It can navigate open-ended prompts and sight-unseen scenarios with remarkable fluency and human-like understanding. Opus shows us the outer limits of what’s possible with generative AI.
Cost Task automation: plan and execute complex actions across APIs and databases, interactive coding R&D: research review, brainstorming and hypothesis generation, drug discovery Strategy: advanced analysis of charts & graphs, financials and market trends, forecasting
[Input $/million tokens | Output $/million tokens] $15 | $75
Context window 200K*
Potential uses
Differentiator Higher intelligence than any other model available.
*1M tokens available for specific use cases, please inquire.

Claude 3 Sonnet strikes the ideal balance between intelligence and speed—particularly for enterprise workloads. It delivers strong performance at a lower cost compared to its peers, and is engineered for high endurance in large-scale AI deployments.
Cost Data processing: RAG or search & retrieval over vast amounts of knowledge Sales: product recommendations, forecasting, targeted marketing Time-saving tasks: code generation, quality control, parse text from images
[Input $/million tokens | Output $/million tokens] $3 | $15
Context window 200K
Potential uses
Differentiator More affordable than other models with similar intelligence; better for scale.
Claude 3 Haiku is our fastest, most compact model for near-instant responsiveness. It answers simple queries and requests with unmatched speed. Users will be able to build seamless AI experiences that mimic human interactions.
Cost Customer interactions: quick and accurate support in live interactions, translations Content moderation: catch risky behavior or customer requests Cost-saving tasks: optimized logistics, inventory management, extract knowledge from unstructured data
[Input $/million tokens | Output $/million tokens] $0.25 | $1.25
Context window 200K
Potential uses
Differentiator Smarter, faster, and more affordable than other models in its intelligence category.
Opus and Sonnet are available to use today in our API, which is now generally available, enabling developers to sign up and start using these models immediately. Haiku will be available soon. Sonnet is powering the free experience on claude.ai, with Opus available for Claude Pro subscribers.
Sonnet is also available today through Amazon Bedrock and in private preview on Google Cloud’s Vertex AI Model Garden—with Opus and Haiku coming soon to both.
Smarter, faster, saferWe do not believe that model intelligence is anywhere near its limits, and we plan to release frequent updates to the Claude 3 model family over the next few months. We're also excited to release a series of features to enhance our models' capabilities, particularly for enterprise use cases and large-scale deployments. These new features will include Tool Use (aka function calling), interactive coding (aka REPL), and more advanced agentic capabilities.
As we push the boundaries of AI capabilities, we’re equally committed to ensuring that our safety guardrails keep apace with these leaps in performance. Our hypothesis is that being at the frontier of AI development is the most effective way to steer its trajectory towards positive societal outcomes.
We’re excited to see what you create with Claude 3 and hope you will give us feedback to make Claude an even more useful assistant and creative companion. To start building with Claude, visit anthropic.com/claude.
Footnotes
This table shows comparisons to models currently available commercially that have released evals. Our model card shows comparisons to models that have been announced but not yet released, such as Gemini 1.5 Pro. In addition, we’d like to note that engineers have worked to optimize prompts and few-shot samples for evaluations and reported higher scores for a newer GPT-4T model. Source.



